
[70]
Поверять алгеброй гармонию—занятие древнее. И нужно отдать справедливость, результаты бывали блестящие. Вспомним хотя бы Пифагора с его анализом колебаний струны. В Новое время эту работу продолжила Лейбниц и Эйлер, Юнг и Гельмгольц. Подробнее об этом можно прочитать в прекрасной книге Г. Анфилова «Физика и музыка» (М., «Детская литература», 1964).
Но незаметно эти исследования соскользнули в область анализа материального фундамента музыки, ее «строительного материала» — звука, в область акустики и физиологии слуха. Аналогично исследования в области живописи переходят в физику и химию красок, в биофизику и психофизиологию зрения. Количественный анализ текстов также тяготеет либо к лингвистике, либо к стилистике, которую можно считать «индивидуальной лингвистикой». Но вне поля зрения естественных наук остается художественное произведение как самостоятель-
[71]
ный феномен. Кроме открытого во времена незапамятные «золотого сечения», диктующего самые общие пропорции художественного целого, за последние две тысячи лет не было найдено ни одной количественной закономерности, существенно связанной не с материалом художественного произведения, а с его формой.
Нельзя сказать, что попытки не делались. И в средние века, и в эпоху Возрождения многие увлекались числовой магией, и совсем не бесплодными были эти занятия. Достаточно вспомнить Иоганна Кеплера с его поисками небесной гармонии. Но именно с точки зрения познания законов искусства ничего существенного не открылось. Может быть, именно потому, что плоды интеллектуального познания пытались непосредственно переносить в творческую практику.
Я держу в руках грампластинку с мессой нидерландского композитора Якоба Обрехта (1430—1505 гг.) «Super Maria Zart» Supraphon 1 12 0464). На лицевой стороне глянцевого конверта — затейливая числовая пирамида. А на оборотной стороне конверта дирижер Мирослав Венгода пишет: «Д-р Маркус ван Кревел напечатал в 1959 г. смелую статью о мессе «Subtuum praesidram», в которой обнаружил поистине фантастическую основу скрытой структуры обрехтовской музыки. В 1964 г. появилась его следующая работа, еще более полная и развернутая, о мессе «Maria Zart».
Давно известно, что художники средневековья не ограничивались в творчестве чисто внешним специфическим материалом своего искусства, т. е. музыкант — звуком, художник — красками и т. п. Все творцы той эпохи исходили из одних и тех же определенным образом стабилизованных основ, поступая в соответствии с определенными общественными правилами, исходящими из философской структуры, принятой в определенную эпоху в определенном месте. Художник трудился не только на основе чувства, как мы могли бы предположить, но и знания: требовалось, чтобы одновременно он был и ученым. Обрехт в совершенстве знал метафизику неоплатонизма и космологию неопифагорейцев, он, несомненно, находился под воздействием исканий Пико делла Мирандолы, первого представителя Ренессанса, познавшего кабалистическое учение и попытавшегося перенести его в христианство. Итак, главное у Обрехта — число и числовой план, взаимосвязь чисел, арифметические и геометриче-
[72]
скне ряды, золотое сечение, символика чисел и имен. Все заранее продумано, все размеры детально рассчитаны и начерчены, каждая музыкальная тема имеет заранее установленную длительность и момент окончания, каждое имя или напоминание определенной личности появляется точно в месте пересечения числовых связей, отвечая соответствующей символике данного имени. Музыкальная композиция у Обрехта подобна кафедральному собору, созданному гениальным архитектором».
Это произведение, таким образом, обладает некоей зашифрованной структурой, предельно ясной для автора, но абсолютно скрытой от слушателя. Расшифровка этой структуры — чисто интеллектуальное мероприятие, не имеющее ничего общего с эстетическим восприятием. И как бы ни относиться к такой музыке (иным она нравится, иные скучают), трудно отделаться от мысли, что она вряд ли ухудшилась, если бы ее форма не имела своего невидимого фундамента[1].
Но вот вопрос: если мало проку в искусстве от невидимых для аудитории структур, создаваемых с помощью нашего радио, то не поискать ли другие структуры, также невидимые, но невидимые не только слушателю (читателю, зрителю), но и автору произведения? Если такие структуры обнаружатся и окажутся при этом достаточно общими, не зависящими от конкретных особенностей произведения, его стиля, жанра и т. д., то это будет означать, что найдены некие универсалии, существенно связанные с теми или иными аспектами эстетического восприятия, самой природы красоты и гармонии. Разумеется, эти общие для произведений искусства закономерности должны быть одновременно еще и специфическими закономерностями, например, они должны разрушаться при том или ином искусственном разрушении произведения искусства; если это закономерности, статистического типа, то должно быть исключено действие «закона больших чисел», когда некая упорядоченность возникает как бы сама собой. Но что искать?
[73]
Любое произведение искусства — это сложно организованное целое, состоящее из множества сравнительно простых элементов. В литературе это — слова, в музыке — звуки, в живописи — краски. За редкими исключениями один элемент легко отделяется от другого, некоторые из них совпадают; например, в предыдущем предложении трижды повторен предлог «в». Семь (точнее, 12) нот в октаве дают огромное разнообразие мелодий; невозможно отказаться от их повторения (запрет на повтор внутри всего лишь двенадцатитоновых мелодических последовательностей; введенный Арнольдом Шенбергом, до неузнаваемости преобразил музыку — вот какая важная штука повтор!). Причем сразу видно, что некоторые элементы повторяются часто, другие же, наоборот, редки. Подсчеты типа какой элемент как часто встречается в произведениях того или иного жанра или автора, лежат в основе стилистического анализа, давно уже доказавшего свою эффективность. Но именно индивидуальность значений частот тех или иных элементов, характеризующая тот или иной стиль, не позволяет отыскать на этом пути общих, не зависящих от индивидуальных особенностей автора закономерностей.
Однако существует совершенно иной подход к изучению количественного состава сообщения. В начале нашего века француз Эсту (J. Estoup) задумал создать систему стенографии на научной основе. Ему пришла в голову здравая мысль: стенографический значок должен быть тем проще, чем чаще встречается то слово, которое он обозначает[2]. Чтобы получить сведения о частотах слов, Эсту составил словарь, который мы сегодня называем частотным. Слова в этом словаре располагаются не по алфавиту, а в порядке убывания частоты их встречаемости в том или ином тексте (или наборе текстов).
По-видимому, Эсту был пытливым и любознательным человеком. Иначе он вряд ли занялся бы делом, весьма далеким от стенографических проблем. Он заметил, что
[74]
можно отвлечься от левой колонки словаря, (где слова), и стал рассматривать только правую колонку (где числа). Оказалось, что если частоту самого частого слова умножить на единицу (т. е. оставить как есть), частоту второго слова умножить на 2, третьего—на 3 и т. д., то получаемые произведения меняются незначительно и можно записать приближенное равенство: p1 × i ≈ const, где p1 — частота i-ro слова в списке, упорядоченном по убыванию частот. В таком виде Эсту и опубликовал свой результат в 1916 г.
Эсту не заметил, что если его равенство переписать в виде функциональной зависимости р от его порядкового номера i:

та мы получим ту самую гармоническую последовательность чисел» которую в незапамятные времена подучил Пифагор для колебаний, струны и которая лежит в основе так называемого натурального звукоряда (а так как все прочие музыкальные звукоряды можно рассматривать в качестве приближении к натуральному, то и всех музыкальных шкал вообще). По-видимому, эта аналогия имеет глубокий смысл (жаль, что в этой статье нет возможности рассмотреть ее подробнее), но основная ценность подхода Эсту не в этом. Частоты слов считали и. до него, но он впервые абстрагировался от самих слов, и стал рассматривать только их частоты. Полученное им обобщение носит чисто количественный характер, из него следует лишь, что десятое, например, по употребительности слово должно иметь в. десять раз меньшую частоту, чем самое употребительное, а слово, стоящее на сотом месте, в сто раз меньшую частоту, но какие это слова, формула не сообщает. Принципиальный характер этого обстоятельства осознался далеко не сразу, и только сейчас мы начинаем понимать, что встретились с закономерностями совершенно новой и весьма странной природы.
Но — по порядку.
Результат Эсту оказался незамеченным и не оцененным современниками. Десять лет спустя к похожему результату пришел сотрудник Телефонных лабораторий фирмы «Белл» Э. Кондон (Е. Condon)—ему частоты слов понадобились для оптимизации телеграфных кодов.
[75]
Еще через десяток лет вышла книга американского лингвиста Ципфа (Georg Zipf) «Психобиология языка». Собственно с этой книги начинается естественнонаучный подход к такой традиционно гуманитарной дисциплине, как лингвистика. И хотя сейчас многие построения Ципфа звучат наивно, великой его заслугой является демонстрация самой возможности говорить о гуманитарных предметах на языке чисел и графиков. Заслуга Ципфа оказалась настолько признанной, что сейчас найденную Эсту и Кондовом закономерность называют «законом Ципфа», хотя Ципф лишь повторил и расширил наблюдения Эсту и Кондона и дал им содержательную интерпретацию.
Считалось, что «закон Ципфа» — языковой закон. Нематематики по простоте душевной считали, чаю pt — просто вероятности слов в нашем языке, и мы наблюдаем частоты слов, «порожденные» этими вероятностями. Математики же снисходительно пожимали плечами и доказывали лингвистам, что если их рассуждения верны, то в нашем языке должно быть гораздо меньше слов, чем их зафиксировано даже в не очень полных словарях.
В самом деле. Сумма всех вероятностей всех слов должна быть равна единице — такова природа вероятностей. Величина К, по оценкам лингвистов, равна приблизительно одной десятой. Суммируем:
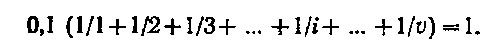
Чтобы это равенство оказалось возможным, сумма в скобках должна равняться 10. Это возможно лишь в том случае, если число членов v заключенного в скобки гармонического ряда будет около 22 000. Меньше нельзя и больше нельзя.
Но в языке не 22 000 слов, а значительно больше! Даже в двуязычных словарях обычно содержится 50—80 тысяч, толковые словари содержат более 100 тысяч, но и это не вce! B толковые словари слова отбираются весьма придирчиво по признаку их «литературности», при это» за бортом остается специальная терминология (например, в 17-томный Толковый словарь АН СССР еще попало слово «триод», но отсутствуют термины того же ряда: «пентод», «тетрод», «октод» и т. п.), всякого рода «непечатная» лексика, жаргоны и т. д. и т. п. По грубым оценкам, «генеральный» словарь языка содержит несколько сот тысяч (до миллиона) слов. Так что число
[76]
22000, следующее из закона Ципфа, непригодно в качестве даже самой грубой оценки “генерального словаря».
Нужно отдать должное Ципфу — он вполне оценил силу этого парадокса (недооцениваемого многими и по сегодняшний день). Во второй своей книге «Человеческое поведение и принцип наименьшего усилия» (1949 г.) он уточнил, что закон может быть справедлив не для всяких лексических выборок, а таких, словарь которых составляет около 22 000 слов. По оценкам Ципфа, объем таких выборок должен быть около двухсот тысяч словоупотреблений. Он назвал этот объем «оптимальным объемом”: при уменьшении выборки ее словарь уменьшался, а при увеличении — увеличивался, и набор частот обнаруживал отклонения от теоретической формулы.
Со стороны это выглядело, конечно же, несолидно. «Подгоняет эксперимент под теорию». И вообще какая-то мистика — что за закон, исключений из которого явно больше, чем правил! И откуда взялись эти двести тысяч, каков их лингвистический смысл? Вопросы эти надолго повисли в воздухе.
Тем временем начался штурм с другого конца. Б. Мандельброт (В. Mandelbrot) в начале 50-х годов подошел к этому закону как кибернетик. Он исследовал процессы оптимизации кодирования. Если слово составлено из букв, а сообщение — из слов, то разумна постановка такой задачи: как соотносятся друг с другом частоты слов в случае, если мы хотим сократить доминируемое общее число букв в сообщении, не теряя его смысла? Оказалось, что если мы выполним кодирование наилучшим способом (при котором наиболее часто употребляемые слова окажутся одновременной самыми короткими), частоты слов выстроятся в такую закономерность:
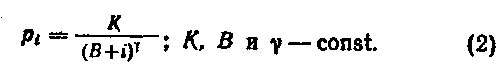
Эта закономерность включает в себя «закон Ципфа» как частный случай. Если константу В положить равной нулю, то формула Мандельброта (2) перейдет в формулу Кондона, а если еще дополнительно положить γ=1, то —в формулу Ципфа (1).
Мандельброт получил свою формулу чисто теоретически. Благодаря большему числу констант эта формула оказалась более гибкой, в частности, лучше описывающей
[77]
зону наиболее частых слов в таких языках, как, например, русский.
Казалось бы, все хорошо. Прояснилась причина, «выстраивающая» частоты слов в упорядоченный ряд,— оптимизация кодирования. Наш язык — в интерпретации Мандельброта — является системой, ответственной за эту оптимизацию. В процессе многовекового развития система языка самооптимизировалась, частоты слов выстроились в определенную последовательность; наиболее часто употребляемые слова действительно короче остальных, по крайней мере в среднем. Попутно найдена более общая форма этой закономерности…
Но неприятности остались. Интерпретация Мандельброта подводила теоретический фундамент под концепцию Ципфа о «языковой» природе этого закона. (Подробнее об этом можно прочесть в книге Дж. Пирса «Символы, сигналы, шумы». М., «Мир», 1967. Это единственная популярная книга на русском языке, рассказывающая о законе Ципфа. Правда, эта фамилия в ней транслитерируется как Зиф.) И ей пришлось взять на себя некоторые следствия этой концепции. Во-первых, если оптимизация происходила в системе языка, то и следствия ее должны носить тоже общеязыковой характер: каждое слово должно обладать постоянной вероятностью употребления. Во-вторых, набор этих общеязыковых вероятностей слов, описываемый формулой (2), должен экспериментально наблюдаться на очень больших выборках, и чем больше мы возьмем выборку, тем точнее наблюденные частоты должны соответствовать теоретическим вероятностям (2).
Ни того ни другого на практике не обнаружилось. На очень больших выборках наблюденные частоты явно не ложились на формулу (2), и чем больше были выборки, тем больше были расхождения. И постоянства частот слов тоже не обнаружилось. Кто-то остроумно заметил: «Достаточно встретить в начале книги слово «лемма», как будешь твердо уверен, что до конца этой книги не встретишь слова «любовь». В разных текстах на одних и тех же местах частотного списка оказывались совершенно различные слова. Так что устойчивость наборов частот оказалось совершенно невозможно объяснить существованием «общеязыковых» вероятностей слов. Да и парадокс «оптимального объема» остался. Правда, в случае формулы Мандельброта (2) этот объем не
[78]
обязательно должен быть равен 200000 словоупотреблений, он может быть любым, но все равно для каждого данного текста такой объем имеет единственное значение. Ситуация похожа на анекдотический закон, связывающий оптимальный возраст невесты с возрастом жениха (я вычитал его в одной из книг Н. Паркинсоиа):
Если жениху 20 лет, невесте должно быть 17; если жениху 40, невесте 27 и т. д. Мы, конечно, не будем вдаваться в проблемы взаимоотношений этого «закона» с реальностью, но обратим внимание вот на какую его черту: для любой пары людей приведенное соотношение может в точности выполняться лишь в один-единственный момент времени. Например, через двадцать лет тому бывшему жениху, которому в момент свадьбы было 20 лет, станет 40, жене же его будет 37 лет, а вовсе не 27, как требует приведенная формула.
Именно таким свойством обладает в закон Эсту— Кондона—Цнпфа—Мандельброта: диктуемые им количественные соотношения могут наблюдаться лишь на выборках некоторого определенного фиксированного объема. На всех остальных объемах неизбежны отклонения. Тот объем, на котором этот закон выполнен точнее всего, естественно назвать «объемом Ципфа» в честь человека, впервые задумавшегося над этим странным обстоятельством.
Приведем основные количественные соотношения, характеризующие «объем Ципфа» в случае, когда константа у в формуле (2) равна единице (по ряду причин этот случай можно полагать практически наиболее важным).
Пусть на «объеме Ципфа» Z самое частое слово встретилось ровно F1 раз. Тогда относительная частота
этого слова будет равна . Абсолютная частота самого редкого слова на лексических выборках неизбежно равна 1 (в любой выборке всегда встречаются — притом
. Абсолютная частота самого редкого слова на лексических выборках неизбежно равна 1 (в любой выборке всегда встречаются — притом
[79]
в большом количестве — слова, каждое из которых встретилось ровно один раз; именно это обстоятельство, в Сущности, и ответственно за парадокс «оптимального объема» — «объема Ципфа»). Следовательно, относительная частота самого редкого слова равна pv=1/Z. Сумма же всех частот, определяемых формулой Мандельброта, должна быть равна единице:
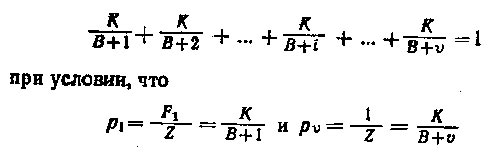
Из этих трех уравнений можно отыскать три величины: К, В и v. Мероприятие не очень простое, поэтому мы не вдаемся в детали решения, получаем:
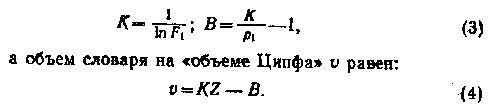
Но в любой лексической выборке всегда очень много разных редких слов, каждое из которых встретилось 1, 2, 3… раза. Этого формула Мандельброта не предусматривает. Если ее понимать буквально, то частоты всех слов должны быть разными. Чтобы согласовать эту зону частот с формулой Мандельброта, нужно допустить, что число разных слов vm, каждое из которых встретилось на выборке объемом Z единиц ровно т раз каждое, равно:

Удивительный смысл у этой формулы. Слов, встретившихся ровно один раз каждое (m= 1), должно быть 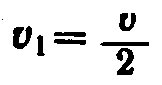 , т. е. половина всего словарного запаса v выборки. Слов, встретившихся по 2 раза каждое, должно быть
, т. е. половина всего словарного запаса v выборки. Слов, встретившихся по 2 раза каждое, должно быть 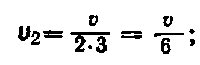 по 3 раза –
по 3 раза – 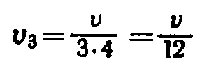 и т.д. Т.е. ред
и т.д. Т.е. ред
и т.д. Т.е. ред[80]
ких слов должно быть чрезвычайно много; в то же время есть небольшая группа очень частых слов в плавный переход между этими группами[3].
Простое разглядывание формул (3) и (4) показывает, что величины К и В в формуле (2), а также словарь выборки о однозначно определяются[4] через ее объем Z и частоту самого частого слова р1(или F1). Относительную частоту самого частого слова в реальных выборках можно считать постоянной. Поэтому основной определяющей величиной является «объем Ципфа» Z. При возрастании Z уменьшаются значения К и В и возрастает словарь v; при уменьшении Z — картина обратная. Если мы рассматриваем выборки, набор частот которых следует закону Ципфа—Мандельброта,
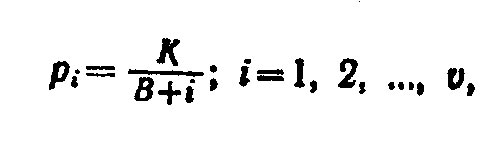
то видим удивительную картину — с изменением их объема Z меняется систематически набор составляющих их частот (рис. 9). С точки зрения обычных статистических представлений такая картина является абсурдом; совершенно немыслимо построить такую статистическую совокупность, на случайных выборках из которых наблюдалась бы такая картина (как совершенно немыслимы муж и жена, для которых все время выполнялось бы «оптимальное соотношение» возраста жениха и невесты). А отсюда следует, что система языка, как нечто единое, никак не может порождать таких закономерностей.
Но тогда откуда же они берутся?
Тривиальная (и весьма популярная) точка зрения
[81]

Рис, 9. Частотные кривые (условно изображены непрерывными линиями) для двух выборок разного объема, каждая из которых выполняет закон Ципфа—Мандельброта. Чем меньше объем выборки, тем раньше обрывается частотный ряд (2). Так как сумма каждого из рядов равна единице, в меньшей выборке весь набор частот идет выше набора частот большей выборки. Объемы выборок на этом рисунке взяты того же порядка, что и крайние объемы музыкальных текстов в табл. 1 (см. ниже). Если мы просуммируем 30 наибольших частот (левее вертикального штрихпунктира) в меньшей выборке, то получим число 0,82. Это доля текста, «покрытого» 30 наиболее частыми элементами. Аналогичная величина для большей выбора составляет 0,59, т. е. с ростом длины текста должна падать доля употреблений наиболее частых элементов (слов и т. п.). Сравните числа 0,82 и 0,59 с фактическими значениями покрытия музыкального текста 30 самыми частыми элементами (8-й столбец табл. 1). Сравнивая, нужно учесть, что частота самого частого элемента в
в реальных текстах нередко заметно отличается от величины 0,1, которая была принята при вычерчивании этих графиков. .Константы К в К”, В и В” вычислены по формулам (3); общее количество разных элементов v — по формуле (4). Жирные площадки в нижней части рисунка, образующие «лесенку» со ступеньками переменной длины, идеализированное представление зоны редких элементов; длины этих ступенек вычисляются по формуле (5).
[82]
сводится к тому, что формулы Эсту—Кондона—Ципфа— Мандельброта просто-напросто являются очень плохим и грубым приближением к реальности. И действительно, очень часто фактические данные реальных выборок вовсе не ложатся на эти формулы, как ни подбирай входящие в них константы. Это обстоятельство стимулирует изобретение всяческих сложных зависимости, призванных лучше аппроксимировать наблюдаемое. Однако на этом пути «чем дальше в лес, тем больше дров», и ничего по-настоящему убедительного, универсально описывающего наблюдаемые факты не появляется.
А если отказаться от поисков универсального и поискать специфику, когда же закон Ципфа все-таки выполняется? И когда можно ожидать, что он будет нарушен? Формулы (2—5) позволяют это сделать очень простым способом, так как в них полностью решена проблема подбора констант, Если договориться считать, что γ=1, Z равен фактическому объему выборки, а р1 — фактически наблюденной частоте наиболее частого слова на этой выборке, то есть теоретический набор частот для данной выборки выстраивается однозначно. А вот лягут ли на него эмпирически наблюденные частоты — это уже совсем другое дело.
Результат подобного сопоставления оказался совершенно ошеломляющим. Формулы (2) — (5) оправдывались почти всегда, когда сравнивались с частотными данными отдельных литературных произведений. И наоборот, они почти никогда не описывали произвольные лексические выборки (отрывки из отдельных произведений и наборы многих текстов в одну выборку, вроде той, которая легла в основу «Частотного словаря русского языка» под редакцией Л. Н. Засориной. М., «Русский язык», 1977).
Другими словами, закон Эсту—Кондона—Ципфа— Мандельброта оказался законом не языка, а текста. Законом отдельного чрезвычайно высокоорганизованного сообщения, рассчитанного на привлечение внимания максимально широкой аудитории. Нехудожественные тексты (научные, технические, философские) выполняли этот закон, если можно так выразиться, с большой на-
тяжкой. Огромные выборки, претендующие представлять «язык в целом», не выполняли его вовсе.
Следует задуматься вот над чем: если мы действительно имеем дело с законом, специфическим для про-
[83]
взведений искусства, то никак нельзя ограничиться анализом только литературного материала.
Но тут встают дополнительные проблемы. В литературных произведениях мы считали такие естественные единицы, как слова. Но что считать, например, в музыке?
Просто звуки — как-то неинтересно. Одна отдельно взятая нота — не музыка ни с какой стороны. Только выслушав две ноты подряд, мы можем ждать какого-то продолжения. Две ноты одну за другой музыканты называют мелодическим интервалом.
Набрали статистику мелодических интервалов в различных текстах композиторов-романтиков. Выстроили набор частот в убывающем порядке. Полученные числа хорошо улеглись на убывающую экспоненту — в точности, как буквы в обычных текстах. Результат и обнадежил, и заставил крепко задуматься. С одной стороны, явная языковая аналогия, явный намек на единство информационных закономерностей. А с другой стороны, буква — не слово, и ждать на этом уровне каких-нибудь специфических закономерностей не приходится. Но что является «музыкальным словом»? Как членить непрерывную мелодию на какие-то музыкальные сегменты, в которых был бы сохранен некий «музыкальный смысл»?
В музыковедении есть мотивы и субмотивы, периоды и фразы, но… Дайте двум музыковедам один и тот же нотный текст и попросите их разбить содержащиеся в нем мелодические последовательности на мотивы — они не сделают этого одинаково. Да еще гордо заявят, что какая-то часть текста на мотивы не разбивается (поспорив предварительно друг с другом, какая это часть)…
Чтобы не быть голословным, процитирую учебник «Музыкальная форма», изданный под редакцией профессора Ю. Н. Тюлина (М., «Музыка», 1974). «Часто оказывается не ясным, представляет ли собой мотив объединение двух (трех или более) небольших интонационных оборотов или же мотивом является каждый из них. В подобных случаях устанавливать их точные границы невозможно, а потому и бессмысленно. Мотивы могут чередоваться мелодическим движением, не имеющим явно мотивного значения. Иначе говоря, они могут возникать на известном расстоянии друг от друга».
Ясно, что мотивы, которые имеет в виду учебник, совершенно непригодны для количественного анализа. И можно лишь пожалеть, что далеко не все музыковедче-
[84]
ские работы, посвященные этим вопросам, так бесстрашно откровенны в признании полной неспособности выделить структурную музыкальную единицу. А без нее нечего и думать начинать что-нибудь считать. Все числа повиснут в воздухе.
Проблему разрешил молодой тбилисский музыковед М. Г. Борода. Базируясь на принятых в музыковедении представлениях о ритмических и метрических тяготениях звуков друг к другу, он выделил строго формальную единицу, которую так и назвал: «формальный мотив» («Ф-мотив»). Он сформулировал правила членения мелодической линии на Ф-мотивы с математической точностью, к сожалению, при этом пришлось сильно поступиться доступностью изложения.
Чтобы составить какое-то (неполное и приблизительное) представление об Ф-мотиве, приведем в порядке приоритета основные правила членения мелодической последовательности звуков на Ф-мотивы:
1. Если в мелодии имеются звуки неравной длительности, то окончание Ф-мотива приходится всегда на звук более долгий, чем последующий, и никогда не может быть перед более долгим звуком.
2. В случае равнодлительных звуков окончание Ф-мотнва приходится на звук, находящийся на более слабой доле такта, чем последующий звук.
Вот как разбивается в соответствии с этими правилами знаменитый «Чижик» (рис. 10, а).
«Чижик» образует первый Ф-мотив, так как третья нота приходится на относительно более сильную долю такта, чем вторая (правило 2). Второй Ф-мотив образован совершенно аналогично. Третий Ф-мотив не может
 «Чижик», б) тема-из второй части Пятой симфонии Чайковского")
[85]
окончиться на втором звуке второго такта, так как третий звук длительнее (правило 1), в результате чего образуется Ф-мотив из трех звуков. Как видно из примера, Ф-мотив — единица переменной длины (как и слово). Практически Длина Ф-мотива колеблется от одного звука (наверное, это соответствует именно тому случаю, когда музыковед скажет, что здесь нет мотива) до пяти звуков подряд (довольно редкая конструкция). Вот пример (тема-из второй части Пятой симфонии Чайковского), в котором на коротком отрезке мелодии встречаются Ф-мотивы всех пяти практически встречающихся длин[5] (рис. 10, б).
В среднем Ф-мотив содержат два с небольшим звука, и (любопытно) эта величина очень мало меняется в зависимости от стиля, жанра и автора.
Кроме правил разбиения мелодических последовательностей на Ф-мотивы, нужно еще задать правила отождествления Ф-мотивов друг с другом. В примере с «Чижиком» совершенно ясно, что первый и второй Ф-мотивы тождественны. Но мелодия может быть сыграна в любой тональности и останется в основном сама собой. Поэтому разумно отождествлять все Ф-мотивы, которые можно преобразовать друг в друга с помощью параллельного .перемещения всех звуков по высоте (так называемого секвентного переноса)[6].
[86]
Таким образом, благодаря представлению об Ф-мотиве можно разбить (однозначно!) мелодическую последовательность на кусочки, имеющее некий «музыкальный смысл» (нигде это разбиение не ощущается как искусственно навязанное мелодии), и притом без пропусков. Важно еще подчеркнуть, что для такого разбиения не нужно заглядывать в нотный текст дальше, чем на одну ноту вперед, и сделать это может даже человек, который, глядя в ноты, не слышит мелодии. Есть и четкое правило отождествления Ф-мотивов друг с другом. Все это позволяет начать подсчеты[7].
Работа эта весьма кропотливая. Нотный текст переписывается на маленькие бумажные карточки — каждое употребление каждого Ф-мотива на отдельную карточку. Затем карточки сортируются таким образом, чтобы одинаковые Ф-мотивы оказались вместе. После их пересчета может быть составлена «словарная картотека» Ф-мотивов. Если ее переткать в порядке убывания частоты Ф-мотивов, получим музыкальный частотный «словарь». Таким способом М. Г. Борода пересчитал около сорока музыкальных текстов, созданных за четыре последних столетия — от Монтеверди до Хиндемита и Шостаковича, Так же как и в случае слов, некоторые Ф-мотивы чрезвычайно употребительны, другие же очень редки и с уменьшением частоты растет число разных Ф-мотивов, имеющих эту частоту. Так, например, в Третьей сонате Шопена 29 разных Ф-мотивов употреблены по 4 раза каждый, 48 Ф-мотивов — по 3 раза, 237 — по 2 раза и по одному разу употреблено 100 разных Ф-мотивов[8].
Итак, и в случае слов средняя длина и сложность Ф-мотивов нарастают с уменьшением их частоты. Если среди самых частых Ф-мотивов преобладают одно- и двухзвуковые, то среди однократно употребленных Ф-мотивов «задают тон» трех- и четырехзвуковые (рис. 11).
[87]
Обращает на себя внимание, что вместе с усложнением ритмической структуры редких Ф-мотивов расширяется и их интервалика, усложняется ладо-гармоническая основа. Все это сильно напоминает мандельбротовскую схему оптимального кодирования, согласно которой более сложные кодовые конструкции должны быть более
редкими.
И действительно, наборы частот Ф-мотивов отдельных музыкальных текстов великолепно укладывались на цип-

Рис. 12. Частотные кривые третьей- сонаты Шопена (верхний график) и прелюдии и фуги И. С. Баха из “Хорошо темперированного клавира» т. 2, № 2 (нижний график). Теоретические кривые изображены, как и на рис. 9, сплошными линиями. Следует подчеркнуть, что никакой подгонки “по точкам» и подбора параметров кривых не производилось, все константы в формуле Мадельброта (2) вычислялись по формулам (3), а исходной ннформацией, для расчета служили лишь полная длина текста Z в количестве Ф-мотивов и абсолютная частота F1 наиболее употребительного Ф-мотива. Константа γ принята равной 1.
[88]
фо-мандельбротовские теоретические кривые, вычисляемые но формулам (2—5). В качестве примера на рис. 12 приведены частотные графики. Характерны примеры таких уникальных Ф-мотивов третьей сонаты Шопена и уникальных Ф-мотивов прелюдии и фуги И. С. Баха на «Хорошо темперированного клавира», т. 2, № 2. В отличие от рис. 9 на рис. 12 изображены не относительные, а абсолютные частоты (в противном случае графики налезают друг на друга и получается неразбериха). Поэтому из рис. 12 нельзя отчетливо разглядеть самое удивительное следствие того обстоятельства, что большая соната (полное число всех «мотивоупотреблений» Z=2364) и сравнительно небольшая прелюдия и фуга (Z = 671) обе выполняют закон Ципфа—Мандельброта — они написаны по-разному. В полном соответствии с рис. 9, на кото-

Рис. 13. Частотные кривые прелюдии я фуги И. С. Баха из ХТК, т. 2, № 22 (верхний график) и отрывка из этого текста — только прелюдии (нижний график). Теоретические кривые вычислялись так же, как и для рис. 12. Легко видеть, что частотная кривая отрывка существенно разошлась со своей теоретической кривой (избыток частых Ф-мотивов при недостатке редких). Как видно из столбца №8 табл. 2, эта ситуация является довольно типичной для отрывков.
[89]
ром частотная кривая для более короткого текста идет выше такой же кривой для текста более длинного, прелюдия и фуга Баха содержат больше часто употребляемых Ф-мотнвов, чем соната Шопена. Если мы просуммируем относительные частоты тридцати наиболее частых Ф-мотнвов в прелюдии и фуге, то получим число 0,70 (т. е. 70% нотного текста составляют 30 наиболее употребительных Ф-мотивов). Аналогичная величина для сонаты равна 0,49.
Но, может быть, это просто стилистические особенности Баха и Шопена? Может быть, Бах более склонен к повторению некоторых найденных формул и «вколачиванию» их в сознание слушателя, а Шопен, композитор-романтик, стремится к разнообразию?
Берем значительно большую прелюдию и фугу

14. Распределение долей цветовых площадей в картине И. Левитана «Над вечным покоем». Теоретическая кривая построена «по точкам» для начального участка кривой (формулы (3—5) выведены для существенно дискретного случая анализа частот, а доля цветовой площади — величина непрерывная, поэтому эти формулы в данном случае не могут «работать» в принципе)
[90]
И. С Баха (ХТК, т. 2, № 22; см. верхний график на рис. 13). Она тоже хорошо укладывается на теоретическую кривую. Если зависимость доли частых элементов от полной длины произведения нам не померещилась, то в данном случае доля тридцати наиболее употребительных Ф-мотивов должна иметь промежуточное значение между первым текстом Баха и сонатой Шопена. И действительно, она равна 0,61. И примерно такое же значение этой величины имеет романтическая Первая баллада (почти в 3 раза меньшая, чем третья соната!) Шопена, т. е. этот показатель не характеризует авторский стиль — он зависит от длины произведения, и зависимость эта носит (в пределах какого-то разброса, разумеется) универсальный характер: чем больше автор художественного произведения собирается сказать, тем меньше он должен повторяться, и наоборот.
Приведенные примеры, конечно, специально подобраны, чтобы пояснить эту мысль. Обозреть весь имеющийся материал нет, разумеется, никакой возможности. В табл. 1 собраны данные о некоторых музыкальных произведениях, созданных за последние три столетия. Произведения упорядочены по возрастанию их полных длин в числе употреблений всех Ф-мотивов (столбец 3). Столбец 4 содержит сведения об относительной частоте употребления наиболее частого Ф-мотива p1 в столбце 5 находится число различающихся Ф-мотивов, так сказать, «Ф-мотивный запас» (по аналогии со «словарным запасом»). Последний, 8-й столбец таблицы (о столбцах 6 и 7 чуть ниже) содержит долю текста, «покрытую» 30 наиболее частыми в этом тексте Ф-мотивами. Легко видеть, что как тенденция уменьшение этой доли с ростом длины текста не подлежит сомнению. Особенно характерно то обстоятельство, что эта доля неизменно уменьшается с ростом длины текста в произведениях одного композитора (ср. тексты Скарлатти, Шопена и Шостаковича).
Табл. 1 содержит еще одну интереснейшую величину— теоретический «Ф-мотивный запас» для данного текста, вычисляемый в предположении, что этот текст (на своем объеме Z и при своем значении F1=p1Z) идеально выполняет закон Ципфа—Мандельброта. Эта теоретическая величина, вычисленная по формуле (4), содержится в столбце 6.
В столбце 7 дано относительное отклонение этих тео-ретических прогнозов от фактических «Ф-мотивных запа-
[91]

[92]
сов» (в процентах). Более чем в половине случаев эти отклонения не превышают 10%; среднее отклонение по всем обследованным сорока текстам (по данным М. Г. Бороды) составляет около 9%, при этом теоретические прогнозы обычно слегка занижены по сравнению с фактическими данными[9].
Картина существенно меняется, если мы нарушим художественное единство и вместо целого произведения возьмем его часть. На нижнем графике рис. 13 изображена частотная кривая только прелюдии (без фуги), ХТК т. 2 № 22, график которых изображен на этом же рисунке вверху.
Человек, знакомый с хрестоматийной статистикой, может сказать, что с уменьшением выборки разброс точек увеличивается: «взяли выборку поменьше, вот и вышло похуже». Но если внимательно приглядеться к нижнему графику на рис. 12 прелюдии и фуги ХТК т. 2 № 2 того же объема, что и объем только прелюдии из № 22, то можно заметить, что малый объем отнюдь не мешает произведению, не подвергшемуся «вивисекции», выполнять закон Ципфа—Мандельброта. Картина эта является типической — нарушение целостности произведения всякий раз приводит к деформации его частотного графика.
Некоторое представление о величине этих деформаций дает табл. 2, в которой собраны данные об отдельных частях некоторых произведений, а также о наборах разных произведений (общего происхождения) в одну выборку. Организована эта таблица так же, как и табл. 1.
Легко видеть, что отклонения теоретических прогнозов от фактических «Ф-мотивных запасов» значительно больше, чем в случае цельных текстов — они достигают 100%. Покрытие текста тридцатью наиболее частыми
[93]

[94]
Ф-мотивами особенно велико в тех случаях, когда фактическое число разных Ф-мотивов в тексте много меньше теоретического прогноза — см. строчки 3, 4, 5 и 8. Так что, по-видимому, не случайно серьезные музыканты никогда не исполняют отдельных частей сонат, как бы ни была «выигрышна» та или иная часть сонаты. И дело тут, видимо, не только в пиетете перед автором музыки — часть написана иначе, чем такое же по объему отдельное произведение[10].
Итак, мы имеем дело со специфической закономерностью свойственной произведению искусства как конечному и замкнутому целому. Закономерность эта, в сущности, ничего не навязывает автору — он волен выбирать любые компоненты, употребляя одни чаще, другие реже, определяя тем самым стиль своего произведения. Но он должен определенным образом дозировать частые и редкие элементы, и дозировка эта определяется такой тотальной характеристикой произведения, как его полная длина.
Но ведь когда произведение пишется, его полная длина как нечто физически реальное еще не существует! Это еще только планы, расчеты, намерения в голове автора. И он, сообразуясь с еще. не существующим целым, должен выдержать определенную стратегию дозировки частых и редких Ф-мотивов. И если нечто похожее на мандельбротовское «оптимальное кодирование» происходит при сотворении музыки, то оно происходит с учетом будущей длины произведения. Необходимость выполнения закона Эсту—Кондона—Ципфа—Мандельброта в некотором смысле индивидуализирует форму и фактуру произведения, заставляя совершенно по-разному подходить к
[95]
“конструированию» отдельного произведения и такой же по длине части более крупного произведения, произведения небольшого и «грандиозного полотна». В общих чертах это было давно известно (в таких примерно, терминах: «сонатная форма сложнее простой трехчастной»; «крупная форма характерна более развитой драматургией»), но никто никогда не задумывался над самой возможностью существования количественной меры этой сложности, не зависящей от индивидуальности автора, от его стиля, эпохи и жанра. И сам автор не подозревает, что в потоке вдохновения он должен считать и контролировать количество употребленных им элементарных мелодических конструкций. Но раз эта титаническая работа происходит решительно никем не замечаясь, значит, она происходит в сокровенных глубинах нашего естества. Осознаем мы, видимо, лишь конечный результат этой работы: недаром про хорошее произведение искусства говорят, что в нем нельзя ничего ни прибавить, ни убавить. И очень крепко сидит в нас это ощущение полноты, законченности, гармоничности целого.[…]
[104]
[…]Произведение искусства есть своего рода тренировочный тест для нашего мозга. Погружая мозг в свою специфическую среду, произведение искусства заставляет его разгадывать свою структуру, прогнозировать вперед и сличать свои прогнозы с реальным развитием. Автор произведения ведет с аудиторией игру, ставка в которой — сама игра. Она должна доставить аудитории удовольствие и именно тем обеспечить себе возможность своего продолжения.
Когда это невозможно?
В двух случаях — когда угадать слишком легко и когда угадать слишком трудно. Автор художественного произведения ходит по лезвию бритвы — малейший крен в любую сторону и публика заскучает. По-видимому, в поисках единственной оптимальной стратегии и выработался тот удивительный инвариант, который мы называем законом Ципфа.
До сих пор в искусстве исследовалось только то, что можно наблюдать в нем непосредственно, так сказать, невооруженным глазом. Самые верхние этажи конструкции: этический, философский, семантический. Выделялись крупные блоки, из которых состоит то или иное произведение: завязка, экспозиция, разработка, реприза… Способы их организации и связи друг с другом: сюжет, композиция, интрига, драматургия, полифония… Слишком много «степеней свободы» на этих уровнях, и единственным обобщением, которое удалось вытащить из их анализа, является признание именно сложности всего построения. Какие-либо общие обязательные закономерности на этих уровнях выделить не удалось: широко распространена точка зрения, согласно которой художник сам устанавливает правила своей игры с аудиторией, а аудитория должна эти правила разгадать и судить о художнике по им самим установленным законам. И каждый крупный мастер прямо-таки «обязан» нарушить каноны своих предшественников.
В сущности, эта концепция выводит искусство за пределы научного анализа. «Единственное», «неповторимое», «уникальное» (не воспроизводимое) не может быть объектом научного исследования. Именно поэтому не поддаются усилиям ученых как телепатия, само сущест-
[105]
вование которой проблематично, так, и несомненно реально существующая шаровая молния. Но победное шествие современной науки началось с того момента, когда информация для научного анализа перестала поступать непосредственно от наших органов чувств. Телескоп и микроскоп, спектрограф и фотометр, циклотрон и камера Вильсона, рентген и масс-спектрометр и многое, многое другое — вот что позволило нам проникнуть в тайны природы существенно дальше Демокрита и Аристотеля. То, что мы непосредственно видим, слышим и осязаем,— лишь ничтожная доля гигантского механизма Природы, лишь начавшего прикрываться нам с помощью наших приборов и нашего разума.
В искусстве, в сущности, то же самое. То, что мы видим и слышим сознательной частью нашего существа,— лишь верхушка гигантского айсберга. Основной поток художественной информации мощно вливается в наше сознание. И именно там действуют невидимые для нас законы, подлинные законы Искусства. И одновременно – законы Природы, законы самой Жизни.
Опубл.: Число и мысль. Вып. 3. М.: Знание, 1980. С. 70 – 105.
размещено 5.10.2008
[1] Похоже, что суперинтеллектуальные конструкция современных композиторов — той же природы, например, «музыкальный палиндром» Стравинского «Памяти Дайлана Томаса», третья часть которого – зеркально, в обратной последовательности повторяет первую. Заметить это на слух решительно невозможно.
[2] Сегодняшний кибернетик сказал бы, что Эсту занялся проблемой статистического согласования кода с каналом связи. Аналогичное согласование производил когда-то и Морзе. В его азбуке (для латинского алфавита) самый простой значок — точка соответствует самой частой (в английских текстах) букве «е»; с уменьшением употребительности буквы усложняется ее морзевский код. Результатом такого согласования является общее уменьшение элементарных символов в сообщении,
[3] Очень похожий закон известен в экономике как «закон Парето». Он описывает распределение людей по получаемым доходам; это, так сказать, «закон социального неравенства». Сходные зависимости известны в экологии, демографии, информатике и мн. др. Можно считать, что подобные зависимости возникают как результат установления некоего равновесия в сложных системах. К сожалению, в данной статье нет возможности коснуться этого интересного вопроса, но любознательного читателя можно отослать к работам Мандельброта, Шрейдера, Козачкова, Ланге.
[4] Читателя-математика следует предупредить, что в рассматриваемой интерпретации выражения (2—5) сами по себе не имеют вероятностного или статистического смысла. Их следует рассматривать как формальные приближения наблюдаемых на выборочных данных зависимостей.
[5] Все границы между Ф-мотивами в данном примере проставляются согласно правилу 1. После ритмически нерасчленимой триольной группировки следуют два звука нарастающих длительностей, образующие совместно с триольной группировкой пятизвуковой Ф-мотив. Второй Ф-мотив образуется аналогично. Третий Ф-мотив — как бы ритмически упрощенный вариант первых двух. За ним следует однозвуковой Ф-мотив (второй звук четвертого такта). В сущности, он является своего рода эмоциональной кульминацией мелодии, после которой начинается слом ее восходящего движения (характерный «надрыв» Чайковского). Если проиграть мелодию, выделяя Ф-мотивы небольшими ударениями и люфт-паузами, то становится наглядно-ясной ее ритмическая структура. Так что Ф-мотивный анализ может быть полезен и в педагогической и исполнительской практике, способствуя прояснению логики музыкальной мысли.
[6] Нужно заметить; что Ф-мотив допускает много вариантов использования. Можно, например, отказаться от анализа звуковысотных соотношений внутри Ф-мотива и рассматривать только его ритмическую структуру (можно при этом выписывать Ф-мотивы на одну нотную линию, как партию барабана). Можно использовать и более обобщенную типизацию Ф-мотивов в целях стилистического анализа, как, например, это сделала ленинградский музыковед Т. Н. Овсянникова.
[7] Следует подчеркнуть, что приведенные правила разбиения, обнажая внутренний смысл предложенной единицы, тем не менее недостаточны для практической работы с ней. Трудности состоят а определении относительно сильных и относительно слабых долей такта в случае сложных размеров. Для их преодоления нужно обратиться к работам М. Г. Бороды и осилить более сложные правила разбиения.
[8] В лексических выборках наиболее распространим однократно употребленные слова {см. формулу (5)), В музыкальных текстах максимум разнообразия нередко приходится на двухразовые Ф-мотивы. Это -связано, как считает М. Г. Борода, с распространенностью музыкальных текстах разного рода реприз.
[9] Максимальное наблюденное отклонение составило 26,8% (соната № 13 Скарлатти). Статистик может заметить, что разброс, достигающий ±20—25%, слишком велик. И он действительно слишком велик, если допустить, что в основе описываемых закономерностей лежит традиционный статистический механизм, вроде случайного выбора шаров из урны. С другой стороны, относительные изменения порядка 10—25% типичны для экспериментальной психологии, когда исследуется способность человека замечать относительные изменения яркости, громкости, тактильного давления и т. п. (известный закон Вебера—Фехнера о постоянстве дифференциального, порога восприятия). Если человек согласует музыкальный «словарь» текста с его полным объемом, он делает это именно с той точностью, с какой ему позволяет это делать природа человеческого восприятия.
[10] Можно заметить из сопоставления табл. 1 и 2, что во всех случаях покрытие текста 30 наиболее частыми Ф-мотивами на частях текста заметно выше, чем на всем тексте в целом. Это связано с тем, что каждая часть имеет свои характерные интонации, не свойственные другим частям; при соединении этих частей средние по всему тексту частоты соответствующих Ф-мотивов, естественно, падают, и тем в большей степени, чем более индивидуализированы части. То же самое происходит и с наиболее употребительными Ф-мотивами: в каждой части оказывается свой «излюбленный» Ф-мотив, который оказывается редким или вовсе отсутствует в других частях. Это обстоятельство свидетельствует о содержательности понятия Ф-мотива, о том, что с помощью этой единицы можно выделять действительно характерные черты музыки.
(1.3 печатных листов в этом тексте)
- Размещено: 01.01.2000
- Автор: Орлов Ю.К.
- Размер: 55.23 Kb
- © Орлов Ю.К.
- © Открытый текст (Нижегородское отделение Российского общества историков – архивистов)
Копирование материала – только с разрешения редакции